Dataset Documentation
Welcome to version 2.14 of the Open Syllabus dataset! Open Syllabus collects and analyzes one of the largest collections of college course syllabi in the world. At a glance:
32,941,092 syllabi (48 billion words of full-text data).
Collected from ~11,000 colleges and universities. Coverage is currently deepest in the US, UK, Australia, and Canada, which together account for about 75% of the corpus.
Spanning roughly 2010 → present. Our earliest documents date back to the late 1990s, but most of the data is concentrated in the last 10 years.
147 million extracted citations to books and articles, spread across 4.4 million unique works.
750 million extracted document sections.
Syllabi are fascinating documents – each one can be thought of as a professional instructor’s opinion about how best to learn about a topic, making them an incredibly rich resource for building tools to support teaching and learning. But, there’s very little standardization in terms of how syllabi are structured, making them difficult to analyze at scale. To aid with this, Open Syllabus builds a document parsing pipeline that converts raw syllabus documents into structured metadata. In many ways this is similar to projects like GROBID that extract metadata from scientific papers; but tailored specifically around syllabi, and capable of handling the range of document types that appear in large corpora of syllabi – PDF documents, DOC(X) documents, HTML pages, and more.
As of version 2.14, the document parser provides:
Normalized document sections – An initial span extraction model maps syllabi into a common schema of 22 section types, abstracting over the variety in the underlying document formats.
Parsed book and article citations – The raw citation strings from the documents are parsed by a second span extraction model, which splits each citation into component parts. These spans are then used to link the citation against a database of ~100 million bibliographic records, which provide standardized metadata for each assigned work – title, authors, year, ISBN/ISSN/DOI, publisher, venue, and more.
Institution – Syllabi are linked against a database of 22,238 institutions, with metadata pulled from IPEDS, Wikidata, and ROR. In many cases, these intitutional associations can be inferred unambiguously from the document URL; but where necessary we fall back to emails and institutions names in the document text.
Date – The year + semester the course was taught, standardizing over a range of different academic calendar types.
Field – The top-level field / department in which the course was taught. Since there’s considerable variety in how departments are structured at different institutions, we classify documents into a taxonomy of 69 top-level fields derived from the Department of Education’s CIP code classifications.
If you’re new to the project, check out our web-facing views onto the data:
Open Syllabus Analytics
A comprehensive view of the dataset designed for universities, publishers, and companies in the education sector. Analytics makes it possible to search the full collection of syllabi and explore the data with powerful aggregations at the level of schools, countries, publishers, fields, and assigned titles. Specialized dashboards make it possible to identify trending topics, track the uptake of OER resources, and build custom reading lists for specific issues and subfields.
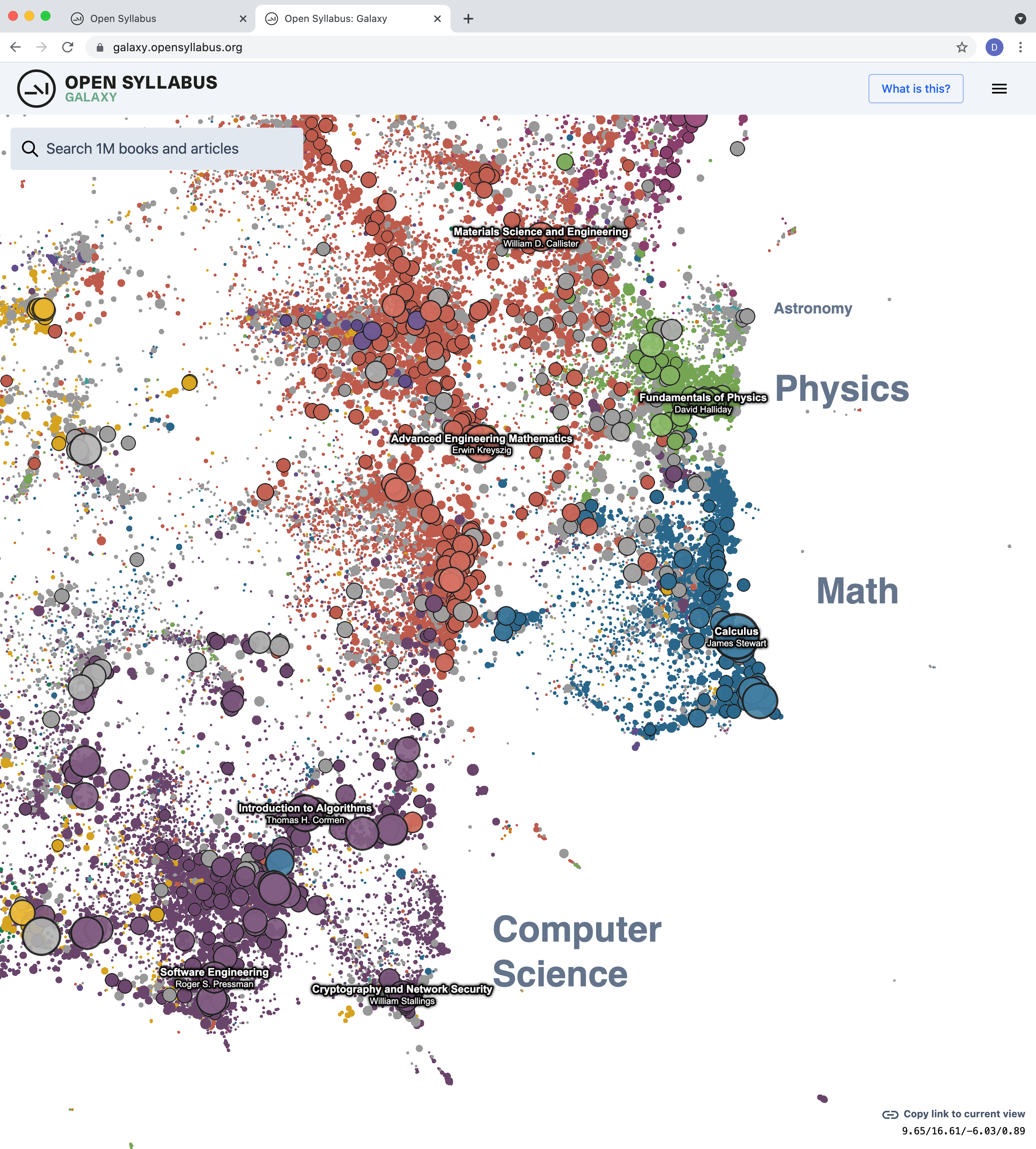
Open Syllabus Galaxy
An interactive recommender system build on the underlying “co-assignment graph” – the network of relationships among books and articles formed by aggregating over all pairs of titles that appear together in the same courses.
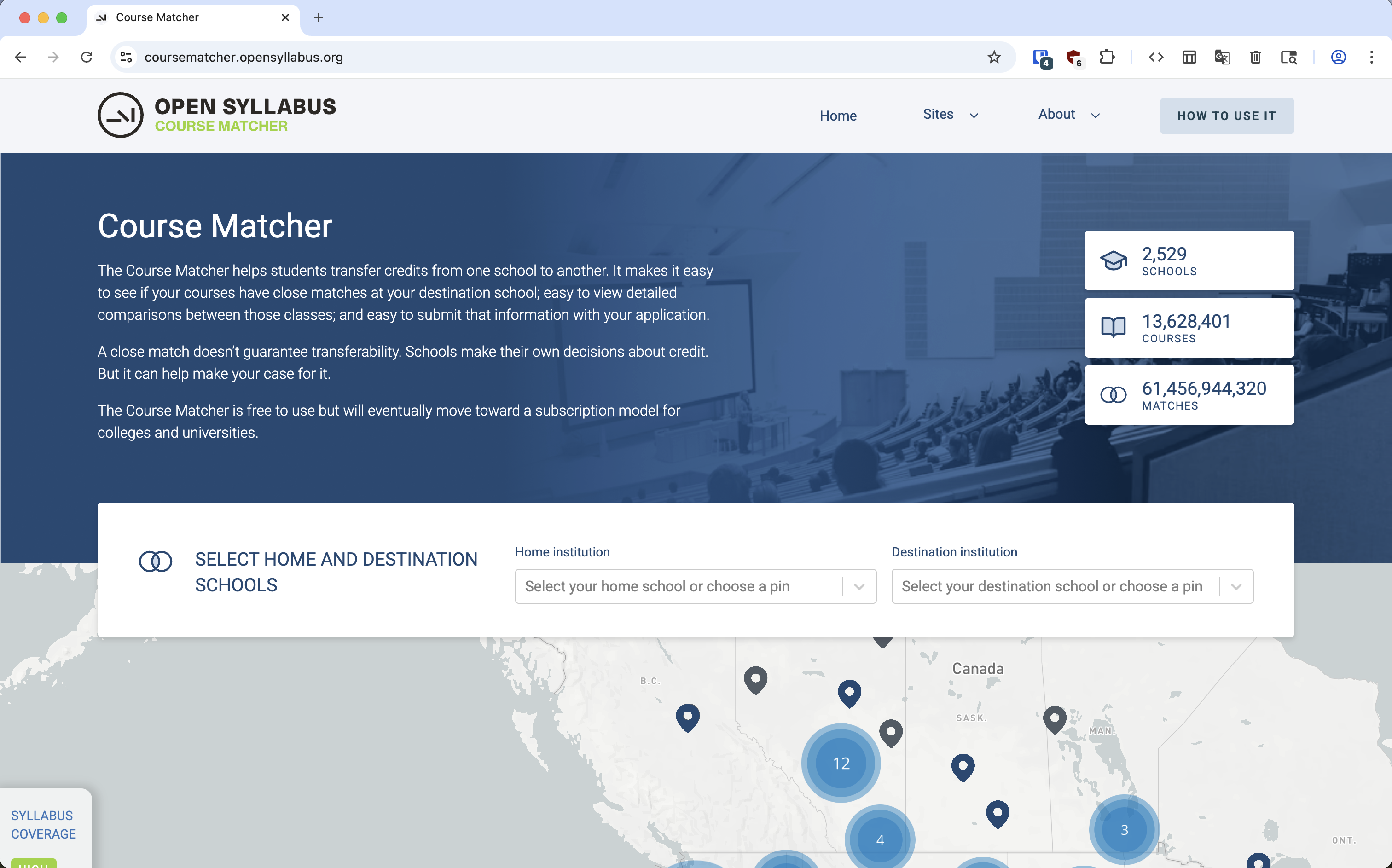
Open Syllabus Course Matcher
A streamlined credit articulation tool designed for students and institutions in the higher education sector. Course Matcher leverages a proprietary curricular mapping framework to identify course equivalencies, explore detailed syllabus comparisons, and simplify the transfer application process. While institutional discretion remains final, the system provides an interactive recommender engine to help users advocate for credit alignment and navigate the transition between schools.